网络爬虫
![]()
使用案例
网络研究是LLM应用中的一个重要应用:
- 用户将其标记为他最想要的AI工具之一。
- 类似gpt-researcher的OSS仓库越来越受欢迎。
概述
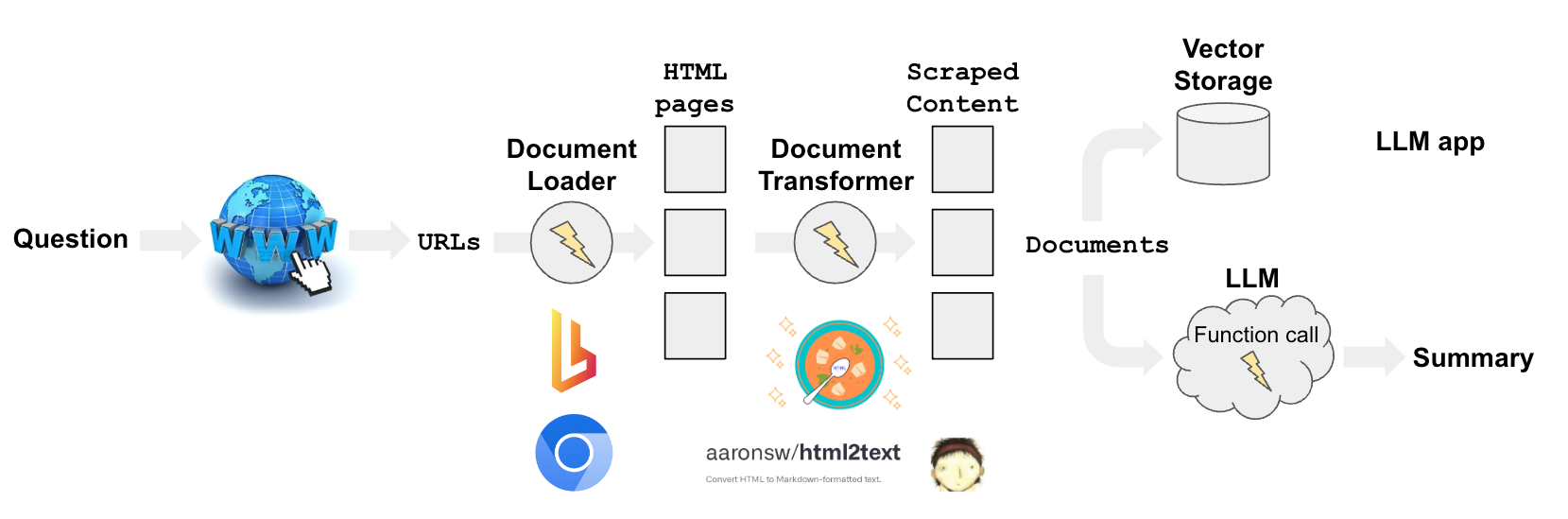
从网络上获取内容有几个组成部分:
搜索:查询URL(例如使用GoogleSearchAPIWrapper)。加载:将URL加载为HTML(例如使用AsyncHtmlLoader、AsyncChromiumLoader等)。转换:将HTML转换为格式化文本(例如使用HTML2Text或Beautiful Soup)。
快速入门
pip install -q openai langchain playwright beautifulsoup4
playwright install
# 设置环境变量OPENAI_API_KEY或从.env文件加载:
# import dotenv
# dotenv.load_env()
使用无头Chromium实例来爬取HTML内容。
使用Python的asyncio库处理异步爬取过程。
使用Playwright处理与网页的实际交互。
from langchain.document_loaders import AsyncChromiumLoader
from langchain.document_transformers import BeautifulSoupTransformer
# 加载HTML
loader = AsyncChromiumLoader(["https://www.wsj.com"])
html = loader.load()
API参考:
- AsyncChromiumLoader 来自
langchain.document_loaders - BeautifulSoupTransformer 来自
langchain.document_transformers
从HTML内容中提取文本内容标签,如<p>、<li>、<div>和<a>标签:
<p>:段落标签。它定义了HTML中的一个段落,用于将相关的句子和/或短语分组在一起。<li>:列表项标签。它用于有序(<ol>)和无序(<ul>)列表中定义列表中的各个项。<div>:分区标签。它是一个块级元素,用于将其他内联或块级元素分组在一起。<a>:锚点标签。它用于定义超链接。<span>:内联容器,用于标记文本的一部分或文档的一部分。
对于许多新闻网站(例如WSJ、CNN),标题和摘要都在<span>标签中。
# 转换
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(html,tags_to_extract=["span"])
# 结果
docs_transformed[0].page_content[0:500]
'English EditionEnglish中文 (Chinese)日本語 (Japanese) More Other Products from WSJBuy Side from WSJWSJ ShopWSJ Wine Other Products from WSJ Search Quotes and Companies Search Quotes and Companies 0.15% 0.03% 0.12% -0.42% 4.102% -0.69% -0.25% -0.15% -1.82% 0.24% 0.19% -1.10% About Evan His Family Reflects His Reporting How You Can Help Write a Message Life in Detention Latest News Get Email Updates Four Americans Released From Iranian Prison The Americans will remain under house arrest until they are '
这些Documents现在可以在各种LLM应用中使用,如下所述。
Loader
AsyncHtmlLoader
AsyncHtmlLoader
使用aiohttp库进行异步HTTP请求,适用于简单和轻量级的爬虫。
AsyncChromiumLoader
AsyncChromiumLoader使用Playwright启动一个Chromium实例,该实例可以处理JavaScript渲染和更复杂的网页交互。
Chromium是Playwright支持的浏览器之一,Playwright是一个用于控制浏览器自动化的库。
无头模式意味着浏览器在没有图形用户界面的情况下运行,这通常用于网络爬虫。
from langchain.document_loaders import AsyncHtmlLoader
urls = ["https://www.espn.com","https://lilianweng.github.io/posts/2023-06-23-agent/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
API参考:
- AsyncHtmlLoader来自
langchain.document_loaders
Transformer
HTML2Text
HTML2Text提供了将HTML内容转换为纯文本(带有类似markdown的格式)的简单方法,而无需进行任何特定的标签操作。 它最适用于需要提取可读性高的文本,而无需操作特定的HTML元素的场景。
Beautiful Soup
Beautiful Soup提供了对HTML内容更精细的控制,可以实现特定标签的提取、删除和内容清理。
它适用于需要提取特定信息并根据需求清理HTML内容的情况。
from langchain.document_loaders import AsyncHtmlLoader
urls = ["https://www.espn.com", "https://lilianweng.github.io/posts/2023-06-23-agent/"]
loader = AsyncHtmlLoader(urls)
docs = loader.load()
API参考:
- AsyncHtmlLoader 来自
langchain.document_loaders
from langchain.document_transformers import Html2TextTransformer
html2text = Html2TextTransformer()
docs_transformed = html2text.transform_documents(docs)
docs_transformed[0].page_content[0:500]
API参考:
- Html2TextTransformer 来自
langchain.document_transformers
"Skip to main content Skip to navigation\n\n<\n\n>\n\nMenu\n\n## ESPN\n\n * Search\n\n * * scores\n\n * NFL\n * MLB\n * NBA\n * NHL\n * Soccer\n * NCAAF\n * …\n\n * Women's World Cup\n * LLWS\n * NCAAM\n * NCAAW\n * Sports Betting\n * Boxing\n * CFL\n * NCAA\n * Cricket\n * F1\n * Golf\n * Horse\n * MMA\n * NASCAR\n * NBA G League\n * Olympic Sports\n * PLL\n * Racing\n * RN BB\n * RN FB\n * Rugby\n * Tennis\n * WNBA\n * WWE\n * X Games\n * XFL\n\n * More"
使用函数调用进行抓取
网页抓取有很多挑战。
其中之一是现代网站布局和内容的不断变化,需要修改抓取脚本以适应这些变化。
使用函数(例如OpenAI)与抽取链,我们避免了在网站变化时不断修改代码的问题。
我们使用gpt-3.5-turbo-0613来确保访问OpenAI函数功能(尽管在撰写时可能对所有人都可用)。
我们还将temperature保持为0,以降低LLM的随机性。
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo-0613")
API参考:
- ChatOpenAI 来自
langchain.chat_models
定义模式(schema):
接下来,您需要定义一个模式来指定您想要提取的数据类型。
在这里,关键名称很重要,因为它们告诉LLM您想要的信息类型。
所以,请尽可能详细。
在这个例子中,我们只想从华尔街日报网站上爬取新闻文章的标题和摘要。
from langchain.chains import create_extraction_chain
schema = {
"properties": {
"news_article_title": {"type": "string"},
"news_article_summary": {"type": "string"},
},
"required": ["news_article_title", "news_article_summary"],
}
def extract(content: str, schema: dict):
return create_extraction_chain(schema=schema, llm=llm).run(content)
API参考:
- create_extraction_chain 来自
langchain.chains
运行使用BeautifulSoup的网络爬虫
如上所示,我们将使用BeautifulSoupTransformer。
import pprint
from langchain.text_splitter import RecursiveCharacterTextSplitter
def scrape_with_playwright(urls, schema):
loader = AsyncChromiumLoader(urls)
docs = loader.load()
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(docs,tags_to_extract=["span"])
print("Extracting content with LLM")
# Grab the first 1000 tokens of the site
splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=1000,
chunk_overlap=0)
splits = splitter.split_documents(docs_transformed)
# Process the first split
extracted_content = extract(
schema=schema, content=splits[0].page_content
)
pprint.pprint(extracted_content)
return extracted_content
urls = ["https://www.wsj.com"]
extracted_content = scrape_with_playwright(urls, schema=schema)
API 参考:
- RecursiveCharacterTextSplitter from
langchain.text_splitter
Extracting content with LLM
[{'news_article_summary': 'The Americans will remain under house arrest until '
'they are allowed to return to the U.S. in coming '
'weeks, following a monthslong diplomatic push by '
'the Biden administration.',
'news_article_title': 'Four Americans Released From Iranian Prison'},
{'news_article_summary': 'Price pressures continued cooling last month, with '
'the CPI rising a mild 0.2% from June, likely '
'deterring the Federal Reserve from raising interest '
'rates at its September meeting.',
'news_article_title': 'Cooler July Inflation Opens Door to Fed Pause on '
'Rates'},
{'news_article_summary': 'The company has decided to eliminate 27 of its 30 '
'clothing labels, such as Lark & Ro and Goodthreads, '
'as it works to fend off antitrust scrutiny and cut '
'costs.',
'news_article_title': 'Amazon Cuts Dozens of House Brands'},
{'news_article_summary': 'President Biden’s order comes on top of a slowing '
'Chinese economy, Covid lockdowns and rising '
'tensions between the two powers.',
'news_article_title': 'U.S. Investment Ban on China Poised to Deepen Divide'},
{'news_article_summary': 'The proposed trial date in the '
'election-interference case comes on the same day as '
'the former president’s not guilty plea on '
'additional Mar-a-Lago charges.',
'news_article_title': 'Trump Should Be Tried in January, Prosecutors Tell '
'Judge'},
{'news_article_summary': 'The CEO who started in June says the platform has '
'“an entirely different road map” for the future.',
'news_article_title': 'Yaccarino Says X Is Watching Threads but Has Its Own '
'Vision'},
{'news_article_summary': 'Students foot the bill for flagship state '
'universities that pour money into new buildings and '
'programs with little pushback.',
'news_article_title': 'Colleges Spend Like There’s No Tomorrow. ‘These '
'Places Are Just Devouring Money.’'},
{'news_article_summary': 'Wildfires fanned by hurricane winds have torn '
'through parts of the Hawaiian island, devastating '
'the popular tourist town of Lahaina.',
'news_article_title': 'Maui Wildfires Leave at Least 36 Dead'},
{'news_article_summary': 'After its large armored push stalled, Kyiv has '
'fallen back on the kind of tactics that brought it '
'success earlier in the war.',
'news_article_title': 'Ukraine Uses Small-Unit Tactics to Retake Captured '
'Territory'},
{'news_article_summary': 'President Guillermo Lasso says the Aug. 20 election '
'will proceed, as the Andean country grapples with '
'rising drug gang violence.',
'news_article_title': 'Ecuador Declares State of Emergency After '
'Presidential Hopeful Killed'},
{'news_article_summary': 'This year’s hurricane season, which typically runs '
'from June to the end of November, has been '
'difficult to predict, climate scientists said.',
'news_article_title': 'Atlantic Hurricane Season Prediction Increased to '
'‘Above Normal,’ NOAA Says'},
{'news_article_summary': 'The NFL is raising the price of its NFL+ streaming '
'packages as it adds the NFL Network and RedZone.',
'news_article_title': 'NFL to Raise Price of NFL+ Streaming Packages as It '
'Adds NFL Network, RedZone'},
{'news_article_summary': 'Russia is planning a moon mission as part of the '
'new space race.',
'news_article_title': 'Russia’s Moon Mission and the New Space Race'},
{'news_article_summary': 'Tapestry’s $8.5 billion acquisition of Capri would '
'create a conglomerate with more than $12 billion in '
'annual sales, but it would still lack the '
'high-wattage labels and diversity that have fueled '
'LVMH’s success.',
'news_article_title': "Why the Coach and Kors Marriage Doesn't Scare LVMH"},
{'news_article_summary': 'The Supreme Court has blocked Purdue Pharma’s $6 '
'billion Sackler opioid settlement.',
'news_article_title': 'Supreme Court Blocks Purdue Pharma’s $6 Billion '
'Sackler Opioid Settlement'},
{'news_article_summary': 'The Social Security COLA is expected to rise in '
'2024, but not by a lot.',
'news_article_title': 'Social Security COLA Expected to Rise in 2024, but '
'Not by a Lot'}]
我们可以将抓取的标题与页面进行比较:

通过查看LangSmith trace,我们可以看到底层的操作:
- 它遵循抽取中所解释的内容。
- 我们在输入文本上调用
information_extraction函数。 - 它将尝试从URL内容中填充提供的模式。
研究自动化
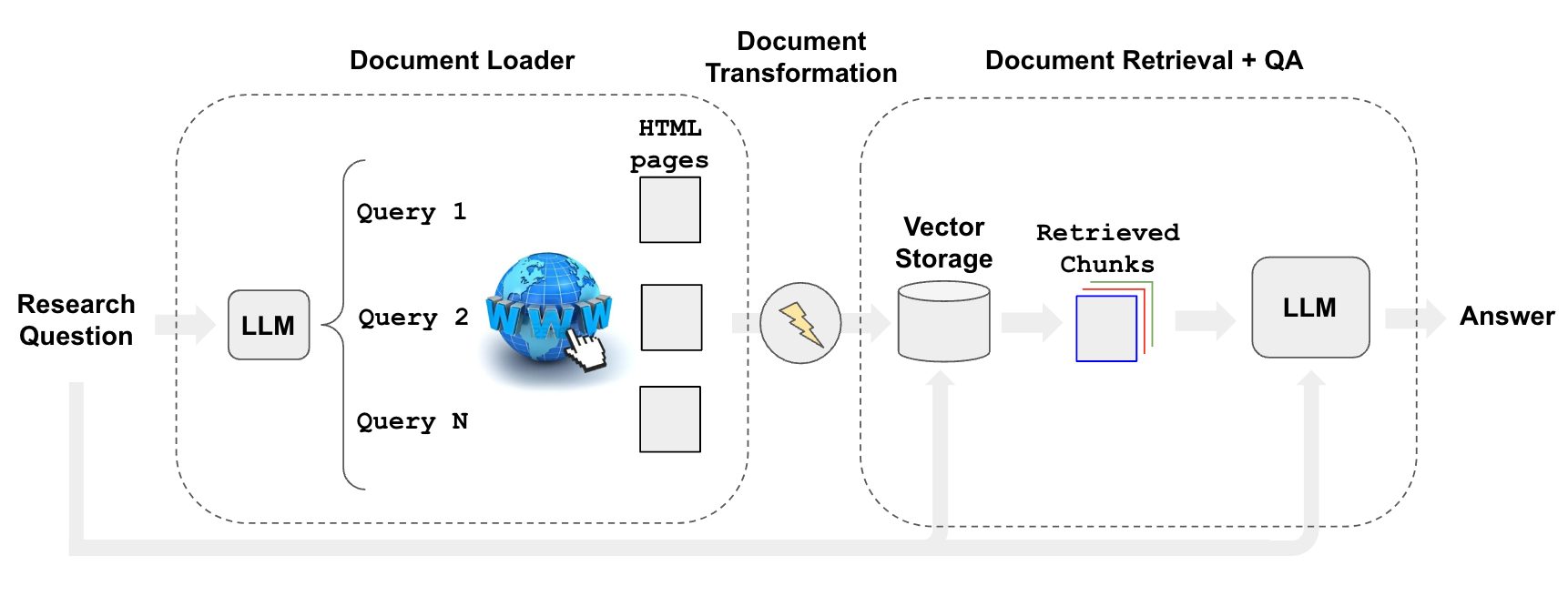
与抓取相关的是,我们可能希望使用搜索内容回答特定问题。
我们可以使用检索器自动化网络研究的过程,例如WebResearchRetriever(docs)。
从这里复制要求requirements.txt:
pip install -r requirements.txt
设置GOOGLE_CSE_ID和GOOGLE_API_KEY。
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models.openai import ChatOpenAI
from langchain.utilities import GoogleSearchAPIWrapper
from langchain.retrievers.web_research import WebResearchRetriever
API 参考:
- Chroma from
langchain.vectorstores - OpenAIEmbeddings from
langchain.embeddings - ChatOpenAI from
langchain.chat_models.openai - GoogleSearchAPIWrapper from
langchain.utilities - WebResearchRetriever from
langchain.retrievers.web_research
# Vectorstore
vectorstore = Chroma(embedding_function=OpenAIEmbeddings(),persist_directory="./chroma_db_oai")
# LLM
llm = ChatOpenAI(temperature=0)
# Search
search = GoogleSearchAPIWrapper()
使用上述工具初始化检索器:
- 使用LLM生成多个相关搜索查询(一个LLM调用)
- 对每个查询执行搜索
- 选择每个查询的前K个链接(并行进行多个搜索调用)
- 加载所有选择的链接的信息(并行抓取页面)
- 将这些文档索引到向量存储器中
- 找到每个原始生成的搜索查询的最相关文档
# Initialize
web_research_retriever = WebResearchRetriever.from_llm(
vectorstore=vectorstore,
llm=llm,
search=search)
# Run
import logging
logging.basicConfig()
logging.getLogger("langchain.retrievers.web_research").setLevel(logging.INFO)
from langchain.chains import RetrievalQAWithSourcesChain
user_input = "How do LLM Powered Autonomous Agents work?"
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm,retriever=web_research_retriever)
result = qa_chain({"question": user_input})
result
API 参考:
- RetrievalQAWithSourcesChain from
langchain.chains
INFO:langchain.retrievers.web_research:Generating questions for Google Search ...
INFO:langchain.retrievers.web_research:Questions for Google Search (raw): {'question': 'How do LLM Powered Autonomous Agents work?', 'text': LineList(lines=['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n'])}
INFO:langchain.retrievers.web_research:Questions for Google Search: ['1. What is the functioning principle of LLM Powered Autonomous Agents?\n', '2. How do LLM Powered Autonomous Agents operate?\n']
INFO:langchain.retrievers.web_research:Searching for relevat urls ...
INFO:langchain.retrievers.web_research:Searching for relevat urls ...
INFO:langchain.retrievers.web_research:Search results: [{'title': 'LLM Powered Autonomous Agents | Hacker News', 'link': 'https://news.ycombinator.com/item?id=36488871', 'snippet': 'Jun 26, 2023 ... Exactly. A temperature of 0 means you always pick the highest probability token (i.e. the "max" function), while a temperature of 1 means you\xa0...'}]
INFO:langchain.retrievers.web_research:Searching for relevat urls ...
INFO:langchain.retrievers.web_research:Search results: [{'title': "LLM Powered Autonomous Agents | Lil'Log", 'link': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'snippet': 'Jun 23, 2023 ... Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1." , "What are the subgoals for achieving XYZ?" , (2) by\xa0...'}]
INFO:langchain.retrievers.web_research:New URLs to load: []
INFO:langchain.retrievers.web_research:Grabbing most relevant splits from urls...
{'question': 'How do LLM Powered Autonomous Agents work?',
'answer': "LLM-powered autonomous agents work by using LLM as the agent's brain, complemented by several key components such as planning, memory, and tool use. In terms of planning, the agent breaks down large tasks into smaller subgoals and can reflect and refine its actions based on past experiences. Memory is divided into short-term memory, which is used for in-context learning, and long-term memory, which allows the agent to retain and recall information over extended periods. Tool use involves the agent calling external APIs for additional information. These agents have been used in various applications, including scientific discovery and generative agents simulation.",
'sources': ''}
深入了解
- 这里有一个应用程序,它使用轻量级用户界面封装了这个检索器。
