聊天机器人 (Chatbots)
![]()
使用案例 (Use case)
聊天机器人是LLM最经典使用案例之一。聊天机器人的核心特点是它们可以进行长时间的对话,并且可以访问用户想要了解的信息。
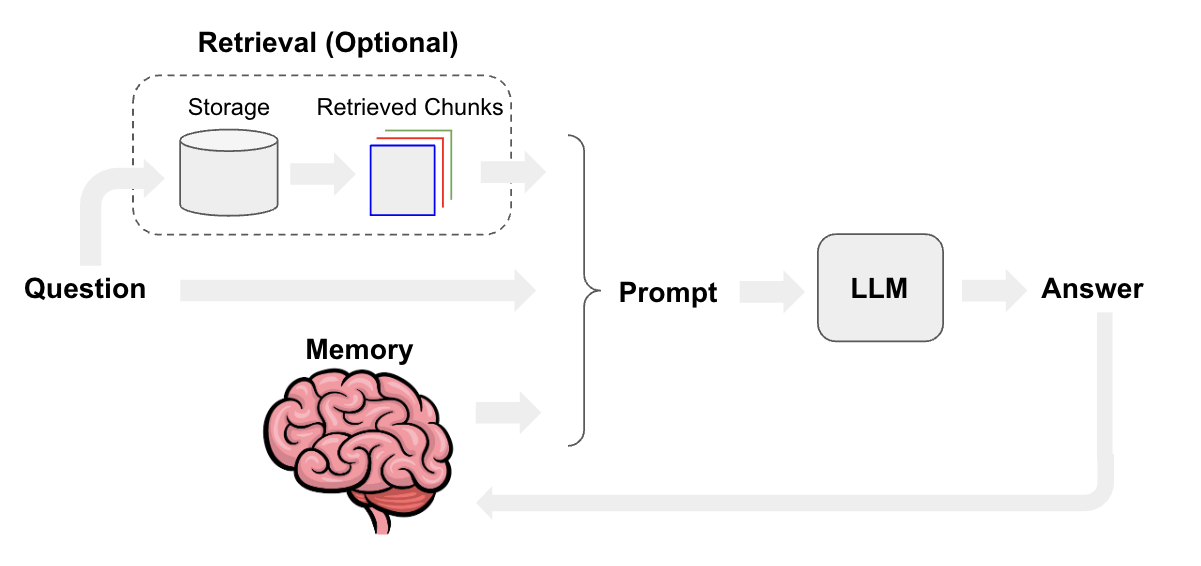
除了基本的提示和LLMs之外,记忆和检索是聊天机器人的核心组成部分。记忆使聊天机器人能够记住过去的互动,而检索则为聊天机器人提供最新的、领域特定的信息。
概述 (Overview)
聊天模型接口基于消息而不是原始文本。在聊天中需要考虑几个重要组件:
聊天模型:请参阅此处以获取聊天模型集成的列表,以及此处以获取LangChain中聊天模型接口的文档。您也可以使用LLMs(请参阅此处)作为聊天机器人,但聊天模型具有更具对话性的语气,并且原生支持消息接口。提示模板:提示模板使得组合默认消息、用户输入、聊天历史和(可选)额外检索到的上下文变得容易。记忆:请参阅此处以获取关于记忆类型的详细文档。检索器(可选):请参阅此处以获取有关检索系统的详细文档。如果您想构建具有特定领域知识的聊天机器人,这些将非常有用。
快速入门 (Quickstart)
以下是我们如何创建聊天机器人界面的快速预览。首先,让我们安装一些依赖项并设置所需的凭据:
pip install langchain openai
# 设置环境变量 OPENAI_API_KEY 或从 .env 文件加载:
# import dotenv
# dotenv.load_env()
使用普通的聊天模型,我们可以通过将一个或多个消息传递给模型来获取聊天完成。
聊天模型将会回复一条消息。
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
chat([HumanMessage(content="将这个句子从英语翻译成法语:I love programming.")])
AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
如果我们传入一个消息列表:
messages = [
SystemMessage(content="你是一个有帮助的助手,可以将英语翻译成法语。"),
HumanMessage(content="我喜欢编程。")
]
chat(messages)
AIMessage(content="J'adore la programmation.", additional_kwargs={}, example=False)
然后,我们可以将聊天模型包装在一个 ConversationChain 中,它内置了记住过去用户输入和模型输出的内存。
from langchain.chains import ConversationChain
conversation = ConversationChain(llm=chat)
conversation.run("将这个句子从英语翻译成法语:I love programming.")
'Je adore la programmation.'
conversation.run("将它翻译成德语。")
'Ich liebe Programmieren.'
内存
正如我们之前提到的,聊天机器人的核心组件是内存系统。其中一种最简单且常用的内存形式是ConversationBufferMemory:
- 这种内存允许将消息存储在一个
buffer中 - 当以链式调用方式调用时,它会返回它存储的所有消息
LangChain还提供了许多其他类型的内存。在这里可以找到关于内存类型的详细文档。
现在让我们快速看一下ConversationBufferMemory。我们可以手动将一些聊天消息添加到内存中,如下所示:
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.chat_memory.add_user_message("hi!")
memory.chat_memory.add_ai_message("whats up?")
现在我们可以从内存中加载。所有Memory类公开的关键方法是load_memory_variables。它接受任何初始链输入,并返回一个添加到链输入的内存变量列表。
由于这种简单的内存类型在加载内存时实际上不考虑链输入,所以我们现在可以传入一个空输入:
memory.load_memory_variables({})
{'history': 'Human: hi!\nAI: whats up?'}
我们还可以使用ConversationBufferWindowMemory来保留最近k个交互的滑动窗口。
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
memory.load_memory_variables({})
{'history': 'Human: not much you\nAI: not much'}
ConversationSummaryMemory是这个主题的扩展。
它会创建一个随时间变化的对话摘要。
这种内存对于较长的对话非常有用,因为完整的消息历史记录会消耗很多标记。
from langchain.llms import OpenAI
from langchain.memory import ConversationSummaryMemory
llm = OpenAI(temperature=0)
memory = ConversationSummaryMemory(llm=llm)
memory.save_context({"input": "hi"},{"output": "whats up"})
memory.save_context({"input": "im working on better docs for chatbots"},{"output": "oh, that sounds like a lot of work"})
memory.save_context({"input": "yes, but it's worth the effort"},{"output": "agreed, good docs are important!"})
memory.load_memory_variables({})
{'history': '\nThe human greets the AI, to which the AI responds. The human then mentions they are working on better docs for chatbots, to which the AI responds that it sounds like a lot of work. The human agrees that it is worth the effort, and the AI agrees that good docs are important.'}
ConversationSummaryBufferMemory进一步扩展了这一点:
它使用标记长度而不是交互次数来确定何时刷新交互。
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=10)
memory.save_context({"input": "hi"}, {"output": "whats up"})
memory.save_context({"input": "not much you"}, {"output": "not much"})
对话
我们可以通过ConversationChain来解析底层的内容。
我们可以指定我们的记忆,ConversationSummaryMemory,也可以指定提示。
from langchain.prompts import (
ChatPromptTemplate,
MessagesPlaceholder,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.chains import LLMChain
# LLM
llm = ChatOpenAI()
# 提示
prompt = ChatPromptTemplate(
messages=[
SystemMessagePromptTemplate.from_template(
"You are a nice chatbot having a conversation with a human."
),
# 这里的`variable_name`必须与记忆对齐
MessagesPlaceholder(variable_name="chat_history"),
HumanMessagePromptTemplate.from_template("{question}")
]
)
# 注意我们将`return_messages=True`以适应MessagesPlaceholder
# 注意`"chat_history"`与MessagesPlaceholder的名称对齐
memory = ConversationBufferMemory(memory_key="chat_history",return_messages=True)
conversation = LLMChain(
llm=llm,
prompt=prompt,
verbose=True,
memory=memory
)
# 注意我们只传入`question`变量 - `chat_history`由记忆填充
conversation({"question": "hi"})
> 进入新的LLMChain链...
格式化后的提示:
系统:你是一个与人类进行对话的友好聊天机器人。
人类:hi
> 完成链。
{'question': 'hi',
'chat_history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='Hello! How can I assist you today?', additional_kwargs={}, example=False)],
'text': 'Hello! How can I assist you today?'}
conversation({"question": "将这个句子从英语翻译成法语:I love programming."})
> 进入新的LLMChain链...
格式化后的提示:
系统:你是一个与人类进行对话的友好聊天机器人。
人类:hi
AI:Hello! How can I assist you today?
人类:将这个句子从英语翻译成法语:I love programming.
> 完成链。
{'question': '将这个句子从英语翻译成法语:I love programming.',
'chat_history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='Hello! How can I assist you today?', additional_kwargs={}, example=False),
HumanMessage(content='将这个句子从英语翻译成法语:I love programming.', additional_kwargs={}, example=False),
AIMessage(content='当然!从英语翻译成法语的"I love programming"的翻译是"J\'adore programmer。"', additional_kwargs={}, example=False)],
'text': '当然!从英语翻译成法语的"I love programming"的翻译是"J\'adore programmer。"'}
conversation({"question": "现在将这个句子翻译成德语。"})
> 进入新的LLMChain链...
格式化后的提示:
系统:你是一个与人类进行对话的友好聊天机器人。
人类:hi
AI:Hello! How can I assist you today?
人类:将这个句子从英语翻译成法语:I love programming.
AI:当然!从英语翻译成法语的"I love programming"的翻译是"J'adore programmer。"
人类:现在将这个句子翻译成德语。
> 完成链。
{'question': '现在将这个句子翻译成德语。',
'chat_history': [HumanMessage(content='hi', additional_kwargs={}, example=False),
AIMessage(content='Hello! How can I assist you today?', additional_kwargs={}, example=False),
HumanMessage(content='将这个句子从英语翻译成法语:I love programming.', additional_kwargs={}, example=False),
AIMessage(content='当然!从英语翻译成法语的"I love programming"的翻译是"J\'adore programmer。"', additional_kwargs={}, example=False),
HumanMessage(content='现在将这个句子翻译成德语。', additional_kwargs={}, example=False),
AIMessage(content='当然!从英语翻译成德语的"I love programming"的翻译是"Ich liebe das Programmieren。"', additional_kwargs={}, example=False)],
'text': '当然!从英语翻译成德语的"I love programming"的翻译是"Ich liebe das Programmieren。"'}
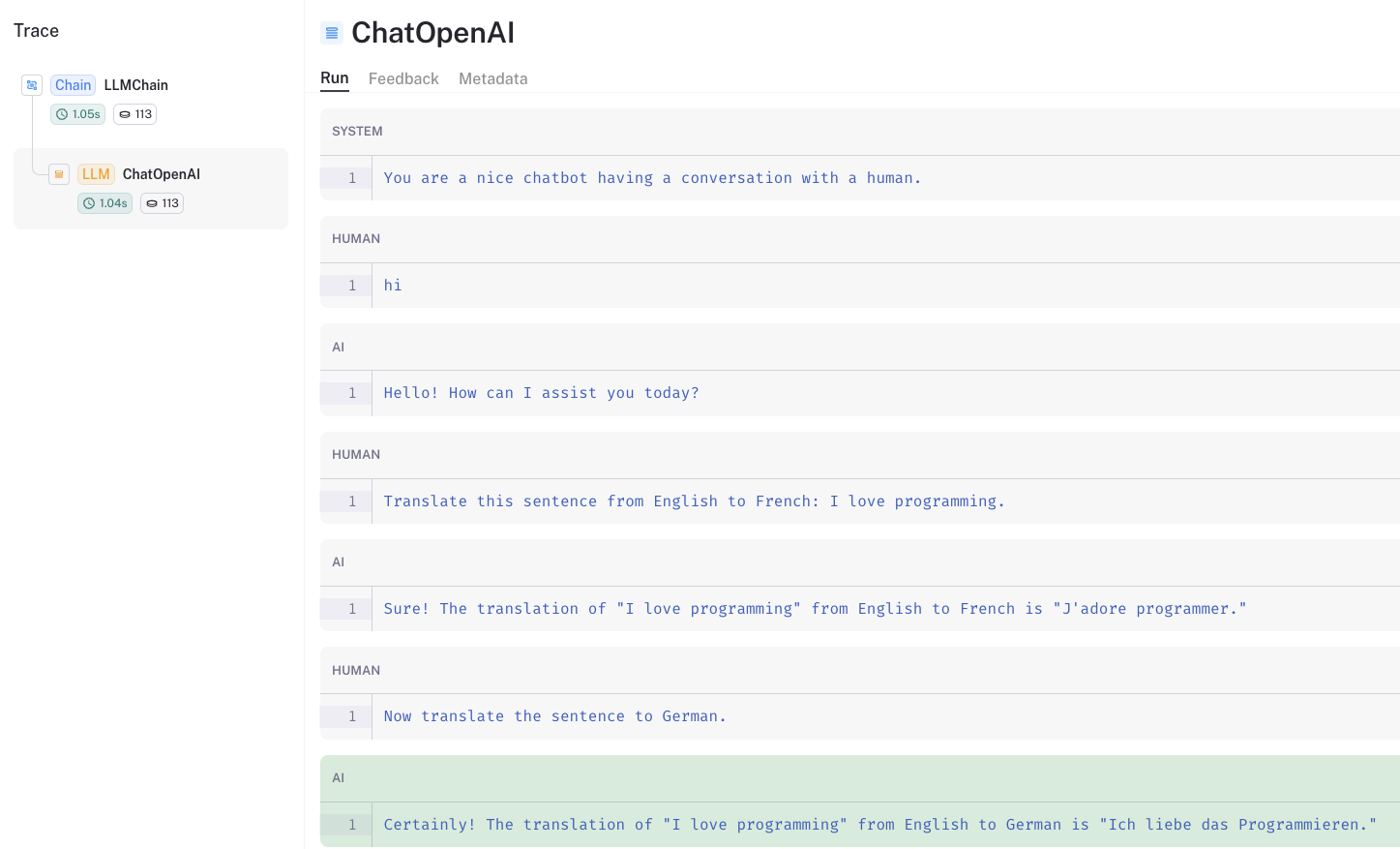
我们可以通过LangSmith trace查看保留在提示中的聊天记录。
聊天检索(Chat Retrieval)
现在,假设我们想要与文档或其他知识来源进行聊天。
这是一个常见的用例,将聊天与文档检索结合起来。
它允许我们与模型未经过训练的特定信息进行聊天。
pip install tiktoken chromadb
加载一个博客文章。
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
将其分割并存储为向量。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
创建我们的记忆,与之前一样,但是让我们使用ConversationSummaryMemory。
memory = ConversationSummaryMemory(llm=llm,memory_key="chat_history",return_messages=True)
from langchain.chat_models import ChatOpenAI
from langchain.chains import ConversationalRetrievalChain
llm = ChatOpenAI()
retriever = vectorstore.as_retriever()
qa = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
qa("How do agents use Task decomposition?")
{'question': 'How do agents use Task decomposition?',
'chat_history': [SystemMessage(content='', additional_kwargs={})],
'answer': 'Agents can use task decomposition in several ways:\n\n1. Simple prompting: Agents can use Language Model based prompting to break down tasks into subgoals. For example, by providing prompts like "Steps for XYZ" or "What are the subgoals for achieving XYZ?", the agent can generate a sequence of smaller steps that lead to the completion of the overall task.\n\n2. Task-specific instructions: Agents can be given task-specific instructions to guide their planning process. For example, if the task is to write a novel, the agent can be instructed to "Write a story outline." This provides a high-level structure for the task and helps in breaking it down into smaller components.\n\n3. Human inputs: Agents can also take inputs from humans to decompose tasks. This can be done through direct communication or by leveraging human expertise. Humans can provide guidance and insights to help the agent break down complex tasks into manageable subgoals.\n\nOverall, task decomposition allows agents to break down large tasks into smaller, more manageable subgoals, enabling them to plan and execute complex tasks efficiently.'}
qa("What are the various ways to implemet memory to support it?")
{'question': 'What are the various ways to implemet memory to support it?',
'chat_history': [SystemMessage(content='The human asks how agents use task decomposition. The AI explains that agents can use task decomposition in several ways, including simple prompting, task-specific instructions, and human inputs. Task decomposition allows agents to break down large tasks into smaller, more manageable subgoals, enabling them to plan and execute complex tasks efficiently.', additional_kwargs={})],
'answer': 'There are several ways to implement memory to support task decomposition:\n\n1. Long-Term Memory Management: This involves storing and organizing information in a long-term memory system. The agent can retrieve past experiences, knowledge, and learned strategies to guide the task decomposition process.\n\n2. Internet Access: The agent can use internet access to search for relevant information and gather resources to aid in task decomposition. This allows the agent to access a vast amount of information and utilize it in the decomposition process.\n\n3. GPT-3.5 Powered Agents: The agent can delegate simple tasks to GPT-3.5 powered agents. These agents can perform specific tasks or provide assistance in task decomposition, allowing the main agent to focus on higher-level planning and decision-making.\n\n4. File Output: The agent can store the results of task decomposition in files or documents. This allows for easy retrieval and reference during the execution of the task.\n\nThese memory resources help the agent in organizing and managing information, making informed decisions, and effectively decomposing complex tasks into smaller, manageable subgoals.'}
同样,我们可以使用LangSmith trace来探索提示结构。
深入探讨 (Going deeper)
- 当需要检索并进行对话时,可以使用代理,例如对话检索代理。
