提取 (Extraction)
![]()
使用案例 (Use case)
获取原始LLM生成的结构化输出很困难。
例如,假设您需要将模型输出格式化为特定模式,以用于:
- 提取结构化行以插入数据库
- 提取API参数
- 提取用户查询的不同部分(例如,用于语义搜索与关键字搜索)
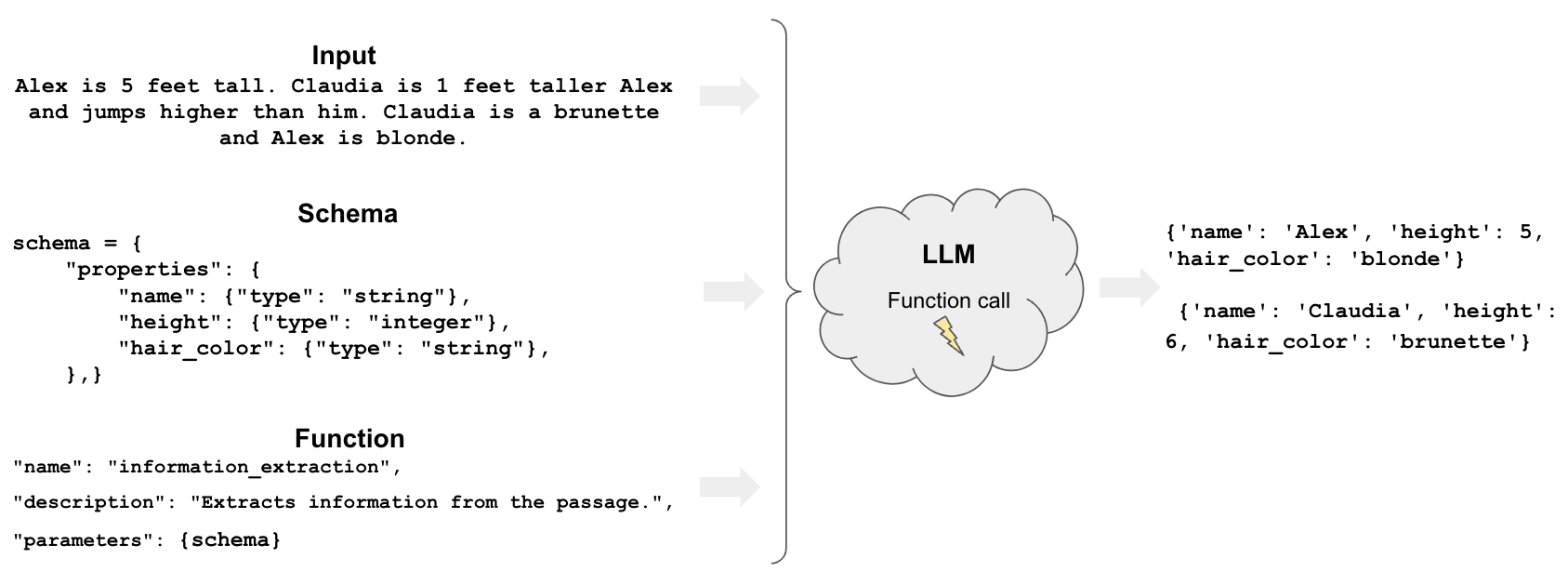
概述 (Overview)
有两种主要方法可以实现这个:
只有一些LLM支持函数(例如OpenAI),而且它们比解析器更通用。
解析器仅提取提供的模式中列举的内容(例如一个人的特定属性)。
函数可以推断出提供的模式之外的东西(例如关于一个人的属性,你没有询问过的)。
快速入门 (Quickstart)
OpenAI函数是开始提取的一种方式。
定义一个模式,指定我们想要从LLM输出中提取的属性。
然后,我们可以使用create_extraction_chain通过OpenAI函数调用来提取我们想要的模式。
pip install langchain openai
# 设置环境变量 OPENAI_API_KEY 或从 .env 文件加载:
# import dotenv
# dotenv.load_env()
from langchain.chat_models import ChatOpenAI
from langchain.chains import create_extraction_chain
# 模式
schema = {
"properties": {
"name": {"type": "string"},
"height": {"type": "integer"},
"hair_color": {"type": "string"},
},
"required": ["name", "height"],
}
# 输入
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde."""
# 运行链
llm = ChatOpenAI(temperature=0, model="gpt-3.5-turbo")
chain = create_extraction_chain(schema, llm)
chain.run(inp)
[{'name': 'Alex', 'height': 5, 'hair_color': 'blonde'},
{'name': 'Claudia', 'height': 6, 'hair_color': 'brunette'}]
选项1:OpenAI功能
窥探内部
让我们深入了解当我们调用create_extraction_chain时发生了什么。
LangSmith跟踪显示我们在输入字符串inp上调用了information_extraction函数。
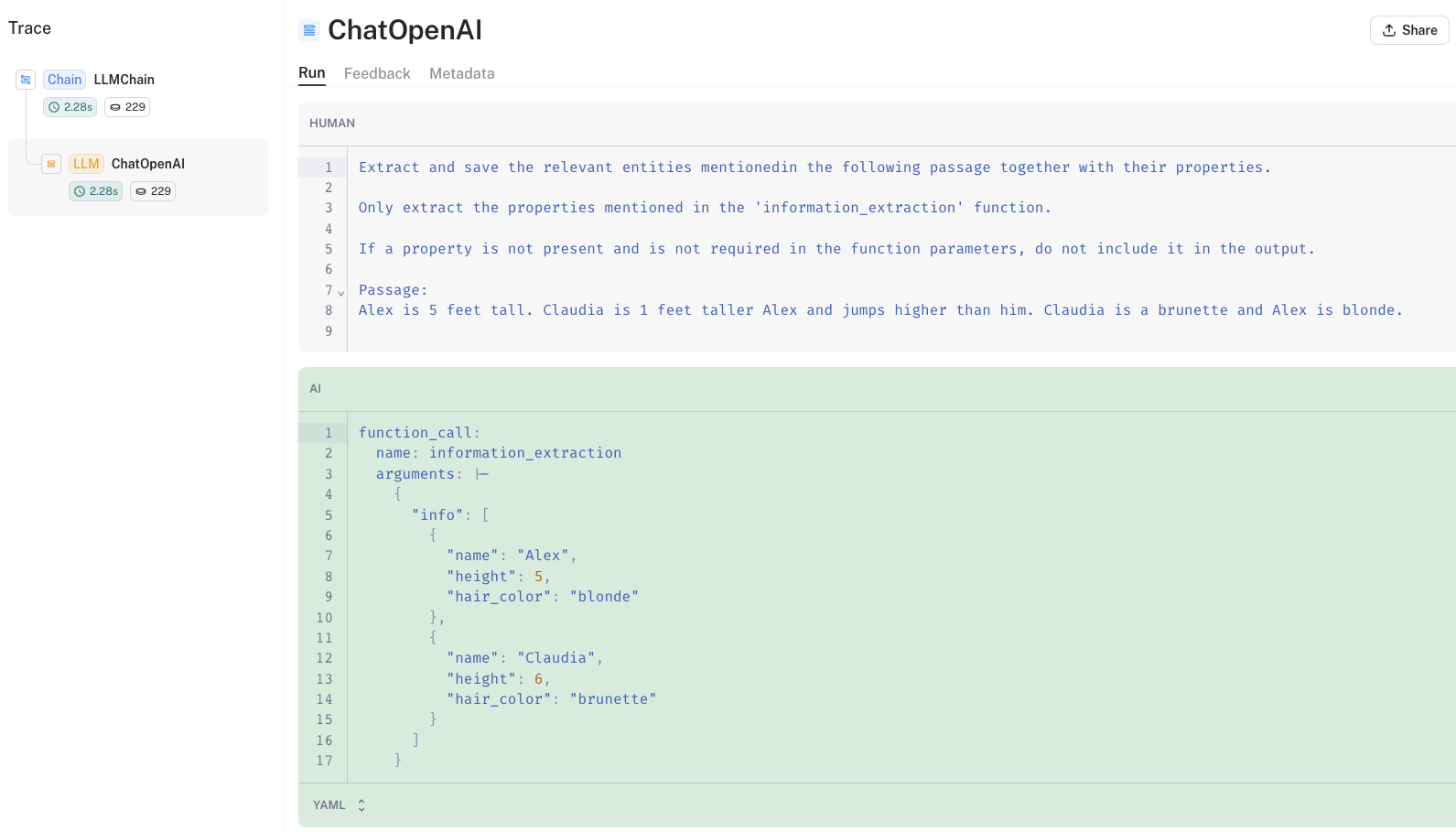
这个information_extraction函数在这里定义,并返回一个字典。
我们可以在模型输出中看到这个字典:
{
"info": [
{
"name": "Alex",
"height": 5,
"hair_color": "blonde"
},
{
"name": "Claudia",
"height": 6,
"hair_color": "brunette"
}
]
}
然后,create_extraction_chain使用JsonKeyOutputFunctionsParser解析原始LLM输出。
这将导致上述链返回的JSON对象列表:
[{'name': 'Alex', 'height': 5, 'hair_color': 'blonde'},
{'name': 'Claudia', 'height': 6, 'hair_color': 'brunette'}]
多个实体类型 (Multiple entity types)
我们可以进一步扩展。
假设我们想区分狗和人。
我们可以为每个属性添加 person_ 和 dog_ 前缀。
schema = {
"properties": {
"person_name": {"type": "string"},
"person_height": {"type": "integer"},
"person_hair_color": {"type": "string"},
"dog_name": {"type": "string"},
"dog_breed": {"type": "string"},
},
"required": ["person_name", "person_height"],
}
chain = create_extraction_chain(schema, llm)
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.
Alex's dog Frosty is a labrador and likes to play hide and seek."""
chain.run(inp)
[{'person_name': 'Alex',
'person_height': 5,
'person_hair_color': 'blonde',
'dog_name': 'Frosty',
'dog_breed': 'labrador'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'}]
不相关的实体 (Unrelated entities)
如果我们使用 required: [],我们允许模型仅返回单个实体(人或狗)的人属性或狗属性。
schema = {
"properties": {
"person_name": {"type": "string"},
"person_height": {"type": "integer"},
"person_hair_color": {"type": "string"},
"dog_name": {"type": "string"},
"dog_breed": {"type": "string"},
},
"required": [],
}
chain = create_extraction_chain(schema, llm)
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde.
Willow is a German Shepherd that likes to play with other dogs and can always be found playing with Milo, a border collie that lives close by."""
chain.run(inp)
[{'person_name': 'Alex', 'person_height': 5, 'person_hair_color': 'blonde'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'},
{'dog_name': 'Willow', 'dog_breed': 'German Shepherd'},
{'dog_name': 'Milo', 'dog_breed': 'border collie'}]
额外信息 (Extra information)
函数的强大之处(相对于仅使用解析器)在于能够执行语义提取的能力。
特别是,我们可以要求获取模式中未明确列举的内容。
假设我们想要关于狗的未指定的额外信息。
我们可以使用占位符进行非结构化提取,dog_extra_info。
schema = {
"properties": {
"person_name": {"type": "string"},
"person_height": {"type": "integer"},
"person_hair_color": {"type": "string"},
"dog_name": {"type": "string"},
"dog_breed": {"type": "string"},
"dog_extra_info": {"type": "string"},
},
}
chain = create_extraction_chain(schema, llm)
chain.run(inp)
[{'person_name': 'Alex', 'person_height': 5, 'person_hair_color': 'blonde'},
{'person_name': 'Claudia',
'person_height': 6,
'person_hair_color': 'brunette'},
{'dog_name': 'Willow',
'dog_breed': 'German Shepherd',
'dog_extra_info': '喜欢和其他狗一起玩'},
{'dog_name': 'Milo',
'dog_breed': 'border collie',
'dog_extra_info': '住得离这里很近'}]
这为我们提供了关于狗的额外信息。
Pydantic (数据验证和设置管理库)
Pydantic是一个用于Python的数据验证和设置管理库。
它允许您创建带有属性的数据类,在实例化对象时自动进行验证。
让我们定义一个带有类型注释的类。
from typing import Optional, List
from pydantic import BaseModel, Field
from langchain.chains import create_extraction_chain_pydantic
# Pydantic数据类
class Properties(BaseModel):
person_name: str
person_height: int
person_hair_color: str
dog_breed: Optional[str]
dog_name: Optional[str]
# 提取
chain = create_extraction_chain_pydantic(pydantic_schema=Properties, llm=llm)
# 运行
inp = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde."""
chain.run(inp)
[Properties(person_name='Alex', person_height=5, person_hair_color='blonde', dog_breed=None, dog_name=None),
Properties(person_name='Claudia', person_height=6, person_hair_color='brunette', dog_breed=None, dog_name=None)]
从trace中可以看出,我们使用了函数information_extraction,如上所示,使用了Pydantic模式。
选项2:解析
输出解析器是帮助结构化语言模型响应的类。
如上所示,它们用于解析create_extraction_chain中OpenAI函数调用的输出。
但是,它们也可以独立于函数使用。
Pydantic(Pydantic)
正如上面所述,让我们基于一个Pydantic数据类来解析一代。
from typing import Sequence
from langchain.prompts import (
PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.llms import OpenAI
from pydantic import BaseModel, Field, validator
from langchain.output_parsers import PydanticOutputParser
class Person(BaseModel):
person_name: str
person_height: int
person_hair_color: str
dog_breed: Optional[str]
dog_name: Optional[str]
class People(BaseModel):
"""Identifying information about all people in a text."""
people: Sequence[Person]
# Run
query = """Alex is 5 feet tall. Claudia is 1 feet taller Alex and jumps higher than him. Claudia is a brunette and Alex is blonde."""
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=People)
# Prompt
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Run
_input = prompt.format_prompt(query=query)
model = OpenAI(temperature=0)
output = model(_input.to_string())
parser.parse(output)
People(people=[Person(person_name='Alex', person_height=5, person_hair_color='blonde', dog_breed=None, dog_name=None), Person(person_name='Claudia', person_height=6, person_hair_color='brunette', dog_breed=None, dog_name=None)])
我们可以从LangSmith跟踪中看到,我们得到了与上面相同的输出。
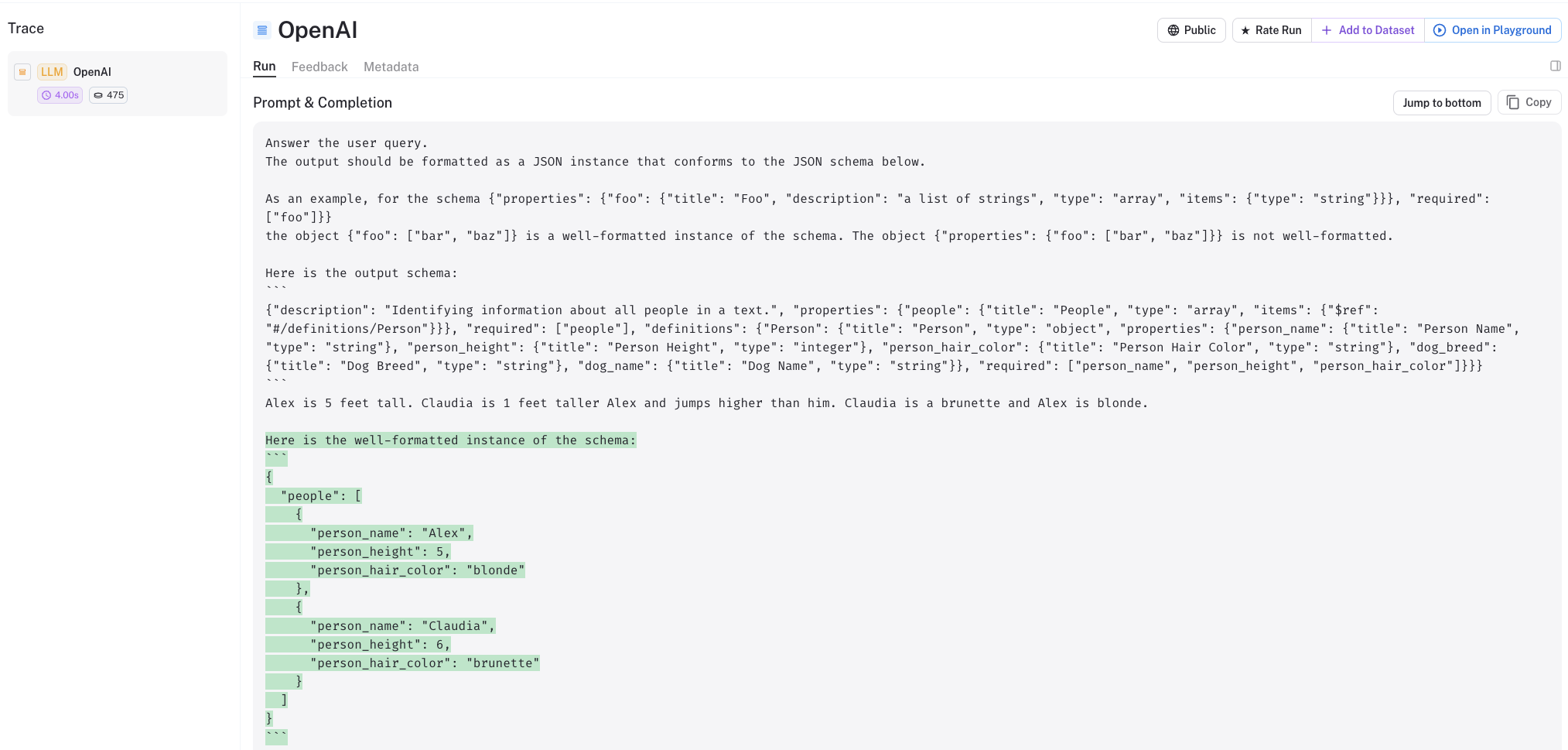
我们可以看到,我们提供了一个两步提示,以便指示LLM以我们期望的格式输出。
而且,我们还需要做更多的工作:
- 定义一个包含多个
Person实例的类 - 显式解析LLM的输出到Pydantic类
我们也可以看到其他情况下的这种情况。
from langchain.prompts import (
PromptTemplate,
ChatPromptTemplate,
HumanMessagePromptTemplate,
)
from langchain.llms import OpenAI
from pydantic import BaseModel, Field, validator
from langchain.output_parsers import PydanticOutputParser
# Define your desired data structure.
class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
# You can add custom validation logic easily with Pydantic.
@validator("setup")
def question_ends_with_question_mark(cls, field):
if field[-1] != "?":
raise ValueError("Badly formed question!")
return field
# And a query intented to prompt a language model to populate the data structure.
joke_query = "Tell me a joke."
# Set up a parser + inject instructions into the prompt template.
parser = PydanticOutputParser(pydantic_object=Joke)
# Prompt
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{query}\n",
input_variables=["query"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# Run
_input = prompt.format_prompt(query=joke_query)
model = OpenAI(temperature=0)
output = model(_input.to_string())
parser.parse(output)
Joke(setup='Why did the chicken cross the road?', punchline='To get to the other side!')
正如我们所看到的,我们得到了一个Joke类的输出,它符合我们最初期望的模式:'setup'和'punchline'。
我们可以查看LangSmith跟踪,以了解底层发生了什么。

深入了解
- 输出解析器文档包含了特定类型(例如列表、日期时间、枚举等)的各种解析器示例。
- JSONFormer提供了另一种对JSON Schema的子集进行结构化解码的方法。
- Kor是另一个用于提取的库,可以向LLM提供模式和示例。
