问答机器人 (QA over Documents)
使用场景:
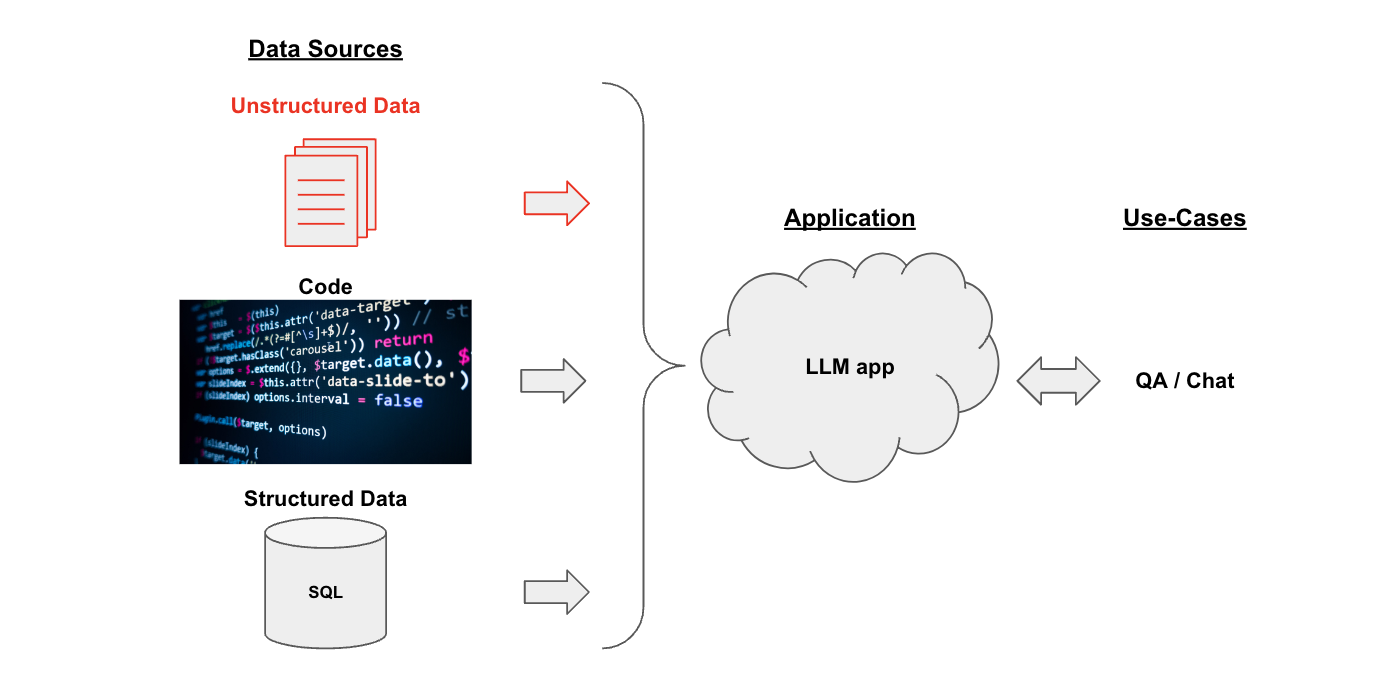
假设您有一些文本文档(PDF、博客、Notion 页面等),并且想要根据这些文档的内容提出问题。由于语言模型在理解文本方面的熟练程度,因此它们是这方面的绝佳工具。
在本教程中,我们将介绍如何使用语言模型构建一个问题回答文档应用程序。我们还在其他地方介绍了两个非常相关的使用案例:
概述 (Overview)
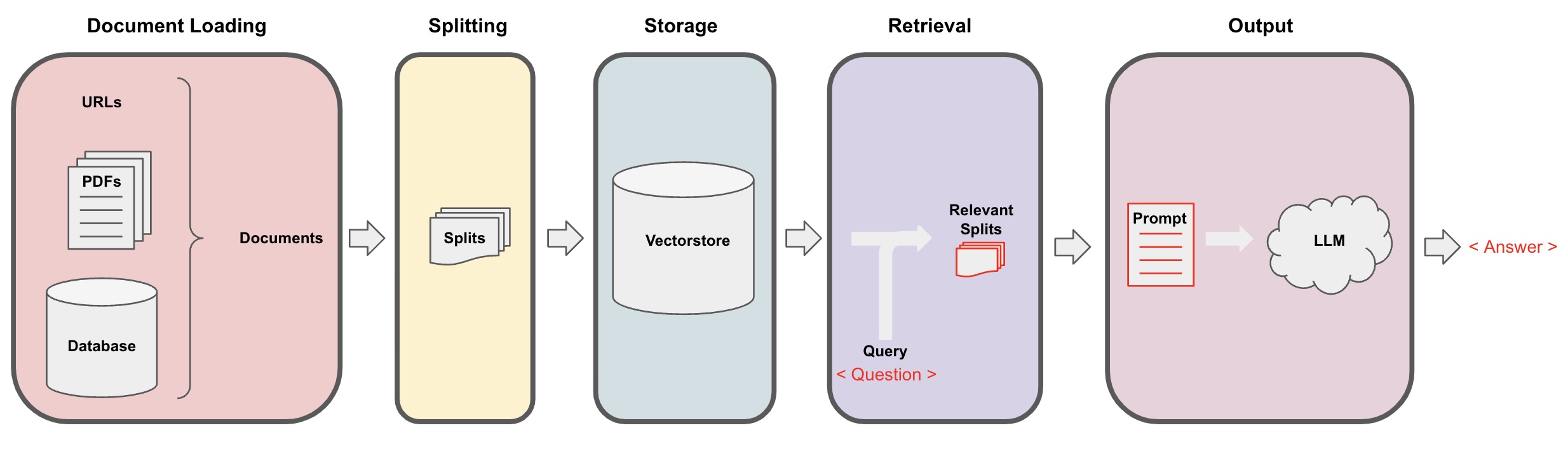
将原始的非结构化数据转换为QA链的流程如下所示:
加载 (Loading): 首先需要加载数据。非结构化数据可以从多个来源加载。使用 LangChain 集成中心 浏览完整的加载器集合。 每个加载器将数据返回为 LangChainDocument。拆分 (Splitting): 文本拆分器 将Documents拆分成指定大小的片段。存储 (Storage): 存储(例如,通常是 vectorstore)将存储并经常嵌入 向量 的拆分片段。检索 (Retrieval): 应用程序从存储中检索拆分片段(通常与输入问题具有相似的嵌入)。生成 (Generation): LLM 使用包含问题和检索数据的提示生成答案。对话 (Conversation)(扩展):通过将 Memory 添加到QA链中进行多轮对话。
快速入门 (Quickstart)
为了给您一个预览,上述流程可以被封装在一个单独的对象中:VectorstoreIndexCreator。假设我们想要在这篇博文上创建一个问答应用程序。我们可以用几行代码来实现:
首先设置环境变量并安装包:
pip install openai chromadb
export OPENAI_API_KEY="..."
然后运行:
from langchain.document_loaders import WebBaseLoader
from langchain.indexes import VectorstoreIndexCreator
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
index = VectorstoreIndexCreator().from_loaders([loader])
现在可以提问了:
index.query("什么是任务分解?")
'任务分解是一种将复杂任务分解为更小、更简单步骤的技术。可以使用LLM进行简单提示、任务特定指令或人工输入来完成。思维树(Yao等人,2023年)是一种任务分解技术的示例,它在每个步骤中探索多个推理可能性并生成多个思考,从而创建了一个树结构。'
好的,但是在底层发生了什么,我们如何根据我们的特定用例进行自定义呢?为此,让我们逐步看一下如何构建这个流程。
步骤 1. 加载
指定一个 DocumentLoader 来加载你的非结构化数据作为 Documents。一个 Document 是一段文本(page_content)和相关的元数据。
from langchain.document_loaders import WebBaseLoader
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
深入了解
步骤2. 分割
将Document分割成用于嵌入和向量存储的块。
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size = 500, chunk_overlap = 0)
all_splits = text_splitter.split_documents(data)
深入了解
DocumentSplitters只是更通用的DocumentTransformers中的一种类型,在预处理步骤中都可以很有用。- 有关转换器的更多文档,请参阅此处。
上下文感知的分割器保留了每个分割在原始Document中的位置("上下文"):
第三步. 存储
为了能够查找我们的文档拆分,我们首先需要将它们存储在我们可以随后查找的地方。 最常见的方法是嵌入每个文档的内容,然后将嵌入和文档存储在一个向量存储中,其中嵌入用于索引文档。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())
深入了解
以下是步骤1-3:
第四步. 检索
使用相似性搜索检索任何问题的相关拆分。
question = "What are the approaches to Task Decomposition?"
docs = vectorstore.similarity_search(question)
len(docs)
4
深入了解 (Go deeper)
向量存储通常用于检索,但它们并不是唯一的选择。例如,SVM(参见此处的线程)也可以使用。
LangChain 有许多检索器,包括但不限于向量存储。所有检索器都实现了一个共同的方法get_relevant_documents()(以及其异步变体aget_relevant_documents())。
from langchain.retrievers import SVMRetriever
svm_retriever = SVMRetriever.from_documents(all_splits,OpenAIEmbeddings())
docs_svm=svm_retriever.get_relevant_documents(question)
len(docs_svm)
4
改进向量相似性搜索的一些常见方法包括:
MultiQueryRetriever生成输入问题的变体以改善检索。最大边际相关性选择检索到的文档中的相关性和多样性。- 在检索过程中可以使用
metadata过滤器对文档进行过滤。
import logging
from langchain.chat_models import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever
logging.basicConfig()
logging.getLogger('langchain.retrievers.multi_query').setLevel(logging.INFO)
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(),
llm=ChatOpenAI(temperature=0))
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
len(unique_docs)
INFO:langchain.retrievers.multi_query:Generated queries: ['1. How can Task Decomposition be approached?', '2. What are the different methods for Task Decomposition?', '3. What are the various approaches to decomposing tasks?']
5
第五步. 生成
使用LLM/Chat模型(例如gpt-3.5-turbo)和RetrievalQA链将检索到的文档提炼成答案。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever())
qa_chain({"query": question})
{
'query': '任务分解的方法有哪些?',
'result': '任务分解的方法包括:\n\n1. 简单提示:这种方法涉及使用简单的提示或问题来引导代理人将任务分解为较小的子目标。例如,可以提示代理人“XYZ的步骤”并要求列出实现XYZ的子目标。\n\n2. 任务特定指令:在这种方法中,为代理人提供任务特定的指令来指导分解过程。例如,如果任务是写一本小说,可以指示代理人“写一个故事大纲”作为子目标。\n\n3. 人类输入:这种方法涉及将人类输入纳入任务分解过程中。人类可以提供指导、反馈和建议,帮助代理人将复杂任务分解为可管理的子目标。\n\n这些方法旨在通过将复杂任务分解为更小、更易管理的部分来实现高效处理复杂任务。'
}
请注意,您可以将LLM或ChatModel(就像我们在这里所做的那样)传递给RetrievalQA链。
深入了解 (Go deeper)
选择LLMs
- 在这里浏览超过55个LLM和聊天模型的集成。
- 在这里查看更多关于LLMs和聊天模型的文档。
- 使用本地LLMs:PrivateGPT和GPT4All的流行凸显了在本地运行LLMs的重要性。使用
GPT4All非常简单,只需下载二进制文件,然后执行以下操作:
from langchain.llms import GPT4All
from langchain.chains import RetrievalQA
llm = GPT4All(model="/Users/rlm/Desktop/Code/gpt4all/models/nous-hermes-13b.ggmlv3.q4_0.bin",max_tokens=2048)
qa_chain = RetrievalQA.from_chain_type(llm, retriever=vectorstore.as_retriever())
自定义提示
在RetrievalQA链中,可以轻松地自定义提示。
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
template = """使用以下上下文片段来回答最后的问题。
如果你不知道答案,只需说你不知道,不要试图编造一个答案。
最多使用三个句子,并尽量简洁地回答。
在回答的结尾总是说"谢谢你的提问!"
{context}
问题:{question}
有用的回答:"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(template)
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
qa_chain = RetrievalQA.from_chain_type(
llm,
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": QA_CHAIN_PROMPT}
)
result = qa_chain({"query": question})
result["result"]
'任务分解的方法有(1)使用LLM的简单提示,(2)使用任务特定的指令,以及(3)使用人类输入。谢谢你的提问!'
返回源文件
可以使用return_source_documents=True返回用于答案提炼的完整文档集。
from langchain.chains import RetrievalQA
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever(),
return_source_documents=True)
result = qa_chain({"query": question})
print(len(result['source_documents']))
result['source_documents'][0]
4
Document(page_content='任务分解可以通过LLM进行,例如使用简单提示,如“XYZ的步骤。\\n1.”,“实现XYZ的子目标是什么?”,或者使用任务特定的说明,例如“编写一个故事大纲。”用于写小说,或者通过人工输入进行。', metadata={'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log", 'description': '使用LLM(大型语言模型)作为核心控制器构建代理是一个很酷的概念。几个概念验证演示,如AutoGPT、GPT-Engineer和BabyAGI,都是鼓舞人心的例子。LLM的潜力不仅限于生成写作流畅的副本、故事、论文和程序;它可以被构建为一个强大的通用问题解决器。\n代理系统概述在一个以LLM为核心的自主代理系统中,LLM作为代理的大脑,辅以几个关键组件:', 'language': 'en'})
返回引用
可以使用 RetrievalQAWithSourcesChain 返回答案引用。
from langchain.chains import RetrievalQAWithSourcesChain
qa_chain = RetrievalQAWithSourcesChain.from_chain_type(llm,retriever=vectorstore.as_retriever())
result = qa_chain({"question": question})
result
{
'question': '任务分解的方法有哪些?',
'answer': '任务分解的方法包括(1)使用简单提示的LLM,(2)使用任务特定的指令,以及(3)结合人类输入。\n',
'sources': 'https://lilianweng.github.io/posts/2023-06-23-agent/'
}
自定义检索文档处理 (Customizing retrieved document processing)
检索到的文档可以通过几种不同的方式传递给 LLM 进行答案提炼。
在这里中很好地总结了将文档传递给 LLM 提示的 stuff、refine、map-reduce 和 map-rerank 链。
stuff 是常用的方式,因为它简单地将所有检索到的文档放入提示中。
使用 load_qa_chain 是一种将文档传递给 LLM 的简单方法,可以使用这些不同的方法 (例如,查看 chain_type)。
from langchain.chains.question_answering import load_qa_chain
chain = load_qa_chain(llm, chain_type="stuff")
chain({"input_documents": unique_docs, "question": question},return_only_outputs=True)
{'output_text': '任务分解的方法包括 (1) 使用简单提示将任务分解为子目标,(2) 提供任务特定的指导来引导分解过程,以及 (3) 结合人类输入进行任务分解。'}
我们还可以将 chain_type 传递给 RetrievalQA。
qa_chain = RetrievalQA.from_chain_type(llm,retriever=vectorstore.as_retriever(),
chain_type="stuff")
result = qa_chain({"query": question})
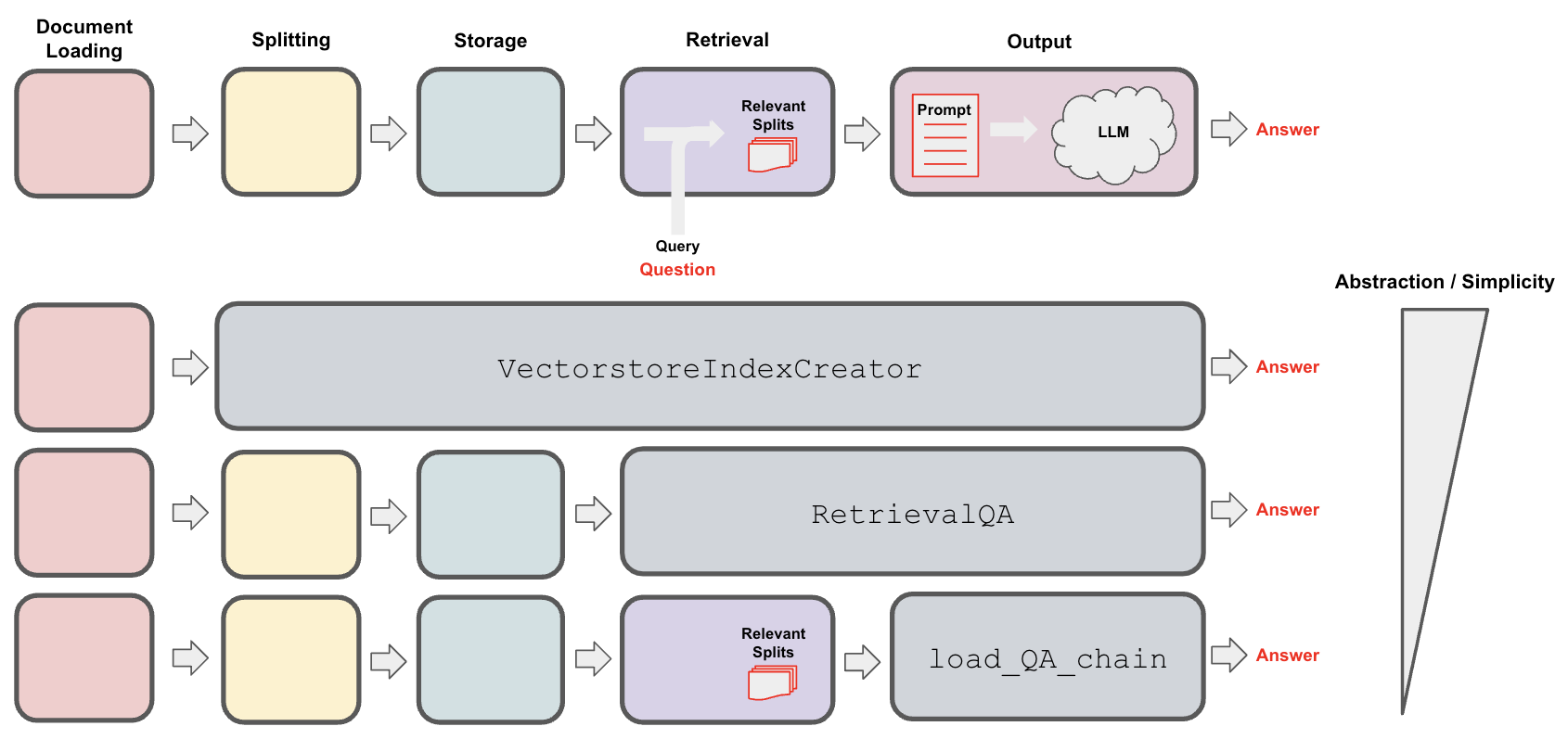
总之,用户可以选择所需的 QA 抽象级别:
第六步:对话(扩展)
为了进行对话,链需要能够引用过去的交互。链Memory可以实现这一点。为了保留聊天历史记录,我们可以指定一个Memory缓冲区来跟踪对话的输入/输出。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
ConversationalRetrievalChain使用Memory缓冲区中的聊天记录。
from langchain.chains import ConversationalRetrievalChain
retriever = vectorstore.as_retriever()
chat = ConversationalRetrievalChain.from_llm(llm, retriever=retriever, memory=memory)
result = chat({"question": "自我反思中的一些主要观点是什么?"})
result['answer']
"自我反思中的一些主要观点包括:\n1. 迭代改进:自我反思允许自主代理通过改进过去的行动决策和纠正错误来提高。\n2. 反复试错:自我反思在不可避免的现实任务中至关重要。\n3. 两次尝试示例:自我反思通过展示失败的轨迹对和理想的反思对来引导未来计划的变化。\n4. 工作记忆:反思被添加到代理的工作记忆中,最多三个,用作查询的上下文。\n5. 绩效评估:自我反思涉及持续审查和分析行动,自我批评行为,并反思过去的决策和策略以改进方法。\n6. 效率:自我反思鼓励聪明和高效,旨在以最少的步骤完成任务。"
Memory缓冲区中的上下文可以解决下面问题中的“it”(“自我反思”)。
result = chat({"question": "《反思论文》如何处理自我反思?"})
result['answer']
"《反思论文》通过向学习语言模型(LLM)展示两次尝试示例来处理自我反思。每个示例包括一个失败的轨迹和一个理想的反思,用于引导代理计划中的未来变化。然后,这些反思被添加到代理的工作记忆中,最多三个,用作查询LLM的上下文。这使得代理能够通过改进过去的行动决策和纠正以前的错误来迭代改进其推理能力。"
深入了解
ConversationalRetrievalChain 的文档提供了一些扩展功能,例如流式处理和源文档。
进一步阅读 (Further reading)
- 查看 How to 部分,了解在不同环境中用于文档问答的各种链的变化。
- 查看 Integrations-specific 部分,了解使用特定集成的链。
