自查询 Self-querying
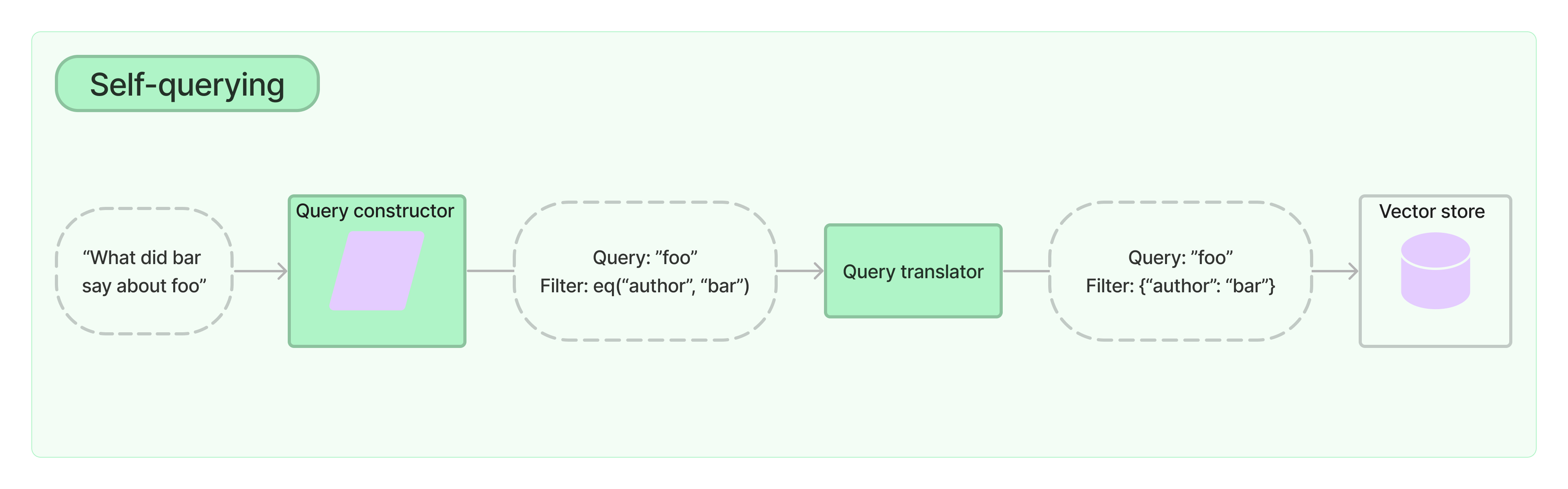
自查询检索器是指具有自我查询能力的检索器。具体而言,给定任何自然语言查询,检索器使用查询构造LLM链来编写结构化查询,然后将该结构化查询应用于其底层的VectorStore。这使得检索器不仅可以使用用户输入的查询与存储文档的内容进行语义相似性比较,还可以从用户查询中提取存储文档的元数据的过滤器,并执行这些过滤器。
开始使用
在这个示例中,我们将使用Pinecone向量存储。
首先,我们需要创建一个Pinecone VectorStore,并使用一些数据进行初始化。我们创建了一个包含电影摘要的小型演示文档集。
要使用Pinecone,您需要安装pinecone包,并且必须拥有API密钥和环境。这里是安装说明。
注意:自查询检索器需要您安装lark包。
# !pip install lark pinecone-client
import os
import pinecone
pinecone.init(api_key=os.environ["PINECONE_API_KEY"], environment=os.environ["PINECONE_ENV"])
from langchain.schema import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
embeddings = OpenAIEmbeddings()
# 创建新的索引
pinecone.create_index("langchain-self-retriever-demo", dimension=1536)
docs = [
Document(page_content="一群科学家带回了恐龙,然后造成了混乱", metadata={"year": 1993, "rating": 7.7, "genre": ["动作", "科幻"]}),
Document(page_content="莱昂纳多·迪卡普里奥迷失在一个梦中的梦中的梦中的...", metadata={"year": 2010, "director": "克里斯托弗·诺兰", "rating": 8.2}),
Document(page_content="一位心理学家/侦探迷失在一系列梦境中,而《盗梦空间》重新使用了这个想法", metadata={"year": 2006, "director": "今敏", "rating": 8.6}),
Document(page_content="一群普通大小的女人非常纯真,一些男人对她们念念不忘", metadata={"year": 2019, "director": "格蕾塔·葛韦格", "rating": 8.3}),
Document(page_content="玩具们活了起来,并且玩得很开心", metadata={"year": 1995, "genre": "动画"}),
Document(page_content="三个人走进区域,三个人走出区域", metadata={"year": 1979, "rating": 9.9, "director": "安德烈·塔可夫斯基", "genre": ["科幻", "惊悚"], "rating": 9.9})
]
vectorstore = Pinecone.from_documents(
docs, embeddings, index_name="langchain-self-retriever-demo"
)
创建自查询检索器
现在我们可以实例化我们的检索器。为此,我们需要提供一些关于我们的文档支持的元数据字段的信息以及文档内容的简要描述。
from langchain.llms import OpenAI
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain.chains.query_constructor.base import AttributeInfo
metadata_field_info=[
AttributeInfo(
name="genre",
description="电影的类型",
type="字符串或字符串列表",
),
AttributeInfo(
name="year",
description="电影的发行年份",
type="整数",
),
AttributeInfo(
name="director",
description="电影导演的姓名",
type="字符串",
),
AttributeInfo(
name="rating",
description="电影的评分(1-10)",
type="浮点数"
),
]
document_content_description = "电影的简要摘要"
llm = OpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(llm, vectorstore, document_content_description, metadata_field_info, verbose=True)
测试一下
现在我们可以尝试使用我们的检索器了!
# 这个示例只指定了一个相关的查询
retriever.get_relevant_documents("有关恐龙的电影有哪些")
query='恐龙' filter=None
[Document(page_content='一群科学家带回了恐龙,然后造成了混乱', metadata={'genre': ['动作', '科幻'], 'rating': 7.7, 'year': 1993.0}),
Document(page_content='玩具们活了起来,并且玩得很开心', metadata={'genre': '动画', 'year': 1995.0}),
Document(page_content='一位心理学家/侦探迷失在一系列梦境中,而《盗梦空间》重新使用了这个想法', metadata={'director': '今敏', 'rating': 8.6, 'year': 2006.0}),
Document(page_content='莱昂纳多·迪卡普里奥迷失在一个梦中的梦中的梦中的...', metadata={'director': '克里斯托弗·诺兰', 'rating': 8.2, 'year': 2010.0})]
# 这个示例只指定了一个过滤器
retriever.get_relevant_documents("我想看一部评分高于8.5的电影")
query=' ' filter=Comparison(comparator=<Comparator.GT: 'gt'>, attribute='rating', value=8.5)
[Document(page_content='一位心理学家/侦探迷失在一系列梦境中,而《盗梦空间》重新使用了这个想法', metadata={'director': '今敏', 'rating': 8.6, 'year': 2006.0}),
Document(page_content='三个人走进区域,三个人走出区域', metadata={'director': '安德烈·塔可夫斯基', 'genre': ['科幻', '惊悚'], 'rating': 9.9, 'year': 1979.0})]
# 这个示例指定了一个查询和一个过滤器
retriever.get_relevant_documents("格蕾塔·葛韦格导演过关于女性的电影吗")
query='women' filter=Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='director', value='Greta Gerwig')
[Document(page_content='一群普通大小的女人非常纯真,一些男人对她们念念不忘', metadata={'director': '格蕾塔·葛韦格', 'rating': 8.3, 'year': 2019.0})]
# 这个示例指定了一个复合过滤器
retriever.get_relevant_documents("评分高于8.5的科幻电影有哪些")
query=' ' filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='genre', value='science fiction'), Comparison(comparator=<Comparator.GT: 'gt'>, attribute='rating', value=8.5)])
[Document(page_content='三个人走进区域,三个人走出区域', metadata={'director': '安德烈·塔可夫斯基', 'genre': ['科幻', '惊悚'], 'rating': 9.9, 'year': 1979.0})]
# 这个示例指定了一个查询和复合过滤器
retriever.get_relevant_documents("1990年后但2005年前关于玩具的电影,最好是动画片")
query='toys' filter=Operation(operator=<Operator.AND: 'and'>, arguments=[Comparison(comparator=<Comparator.GT: 'gt'>, attribute='year', value=1990.0), Comparison(comparator=<Comparator.LT: 'lt'>, attribute='year', value=2005.0), Comparison(comparator=<Comparator.EQ: 'eq'>, attribute='genre', value='animated')])
[Document(page_content='玩具们活了起来,并且玩得很开心', metadata={'genre': 'animated', 'year': 1995.0})]
过滤器k
我们还可以使用自查询检索器来指定k:要获取的文档数量。
我们可以通过将enable_limit=True传递给构造函数来实现这一点。
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True,
verbose=True
)
# 这个示例只指定了一个相关的查询
retriever.get_relevant_documents("有关恐龙的两部电影")
